AIパフォーマンス最大化:レイテンシ制約のある推論サービスにおけるAMD EPYC 9575F CPUの役割
2025-07-14更新

重要ポイント
ジェネレーティブAIを活用したリアルタイムのエージェント型アプリケーションの台頭により、推論処理のレイテンシ(遅延)に関する性能基準が大幅に引き上げられています。
AMD EPYC™ 9575FホストCPUは、レイテンシ制約のある推論サービスを大幅に改善し、Intel XeonホストCPUと比較して10倍以上のパフォーマンスを発揮します¹。
ホストCPUの重要性
AIワークロードではその高い処理能力からGPUが注目されがちですが、適切なCPUを選ぶことでGPU投資の効果を大幅に高めることができます。エージェント型AIの登場により、大規模言語モデル(LLM)のサービスに対してより厳しい性能要件が課される中、ホストCPUの選択はエージェント型AIシステムの応答性に決定的な影響を与えます。
AMDがGPUクラスタ上で動作するAI推論ワークロードを対象に行った社内パフォーマンス分析では、推論サービスの高速化におけるCPUの重要性を示す以下の主要要因が明らかになっています:
・ランタイム:レイテンシが制約条件となり、重複しない前処理を含む場合、高性能CPUはエンドツーエンドのワークロード性能を加速します。
・オーケストレーション:特にMixture-of-Expert(MOE)モデルにおける集合的な演算はCPUクロック周波数に敏感であり、全体性能に影響を及ぼします。
・新しいモデルアーキテクチャ:モデル構造の進化に伴い、新しいモデルやランタイムはGPU展開に最適化されていない場合があり、CPU性能の重要性が一層高まります。
・コントロールプレーン:CPUはGPUノード間の通信を管理するコントロールプレーンの運用に重要な役割を果たします。
・エージェント型AI:エージェント型AIの進化に伴い、推論サービスに対する性能制約はさらに厳しくなっていきます。
AMD EPYC™ 高周波プロセッサの概要
第5世代AMD EPYC™ CPUには、アクセラレータープラットフォームのホスティング向けに特化した高クロック周波数のプロセッサオプションが含まれています。これらのCPUは、データ移動のオーケストレーションや複数の仮想マシンの管理に優れており、GPUノードからより高いパフォーマンスを引き出すために重要な能力を備えています。
最大64コア、最大5GHzの高クロック周波数、および最大6TBのメモリ対応といった仕様により、第5世代AMD EPYC™ CPUはGPUクラスタのホスティングに特化した複数の強力なプロセッサオプションを提供します。
実際、本ホワイトペーパーで公開されたベンチマークデータによれば、コアのクロック周波数向上がAIワークロードの高速化に寄与していることが示されています。

図1:AMD EPYC™ 高周波プロセッサ
レイテンシとスループットのバランス
推論サービスにおいてスループットはGPUおよびシステムの利用率を示す重要な指標であり、高いスループットは良好なGPU利用率を意味します。一方でレイテンシも同様に重要であり、システムの応答性や使いやすさを示す指標となります。
レイテンシの重要性は、リアルタイムアプリケーションを対象としたML Perf Interactiveベンチマークの派生版によって強調されています。人気の大規模言語モデル(LLM)サービスプラットフォームのユーザーデータ解析に基づき、ML Perf Llama2 70B推論サービスのインタラクティブベンチマーク[1]では以下の厳しいレイテンシ目標が設定されています。
- 最初のトークン生成まで450ミリ秒(99パーセンタイル)
- 出力トークンごとに40ミリ秒(99パーセンタイル)
ML Perfインタラクティブモード推論サービスベンチマーク(バージョン4.0で導入)は、ユーザー体験とシステム効率のバランスを重視し、リアルタイムアプリケーションで典型的なレイテンシ制約を反映するよう設計されています。これにより、こうした条件下でのシステム性能をより正確に評価できます。
推論ワークロードにおいて、高スループットと低レイテンシの両立は難しい課題です。一般的に、バッチサイズを増やすことでスループットは向上しますが、その分レイテンシは高くなる傾向があります。逆に、レイテンシを最適化し小さなバッチサイズで処理するとスループットは下がりますが処理は高速化します。
しかしながら、高性能なAMD EPYC™ 9575F CPUを活用することで、レイテンシとスループットのより最適なバランスを実現でき、システム全体の効率を向上させることが可能です。
Intel XeonホストCPUとの比較分析
以下は、2ソケットCPUを搭載した8GPUシステム上で、vLLM推論ランタイムを用いてLlama-3.3-70B(TP8構成)をサービスした際の推論性能を示しています。レイテンシ制約付きスループット(「グッドプット」とも呼ばれる)を、最初のトークン生成までの時間制約(300ms、400ms、500ms、600ms)に対してプロットしています。
300msの制約では、Intel Xeon 8592+プロセッサ搭載システムではグッドプットが観測されませんでした。
一方、400msの制約においては、AMD EPYC™ 9575Fホストプロセッサ搭載システムは、Intel Xeonホストプロセッサ搭載システムと比較して10倍以上のグッドプットを示しました。
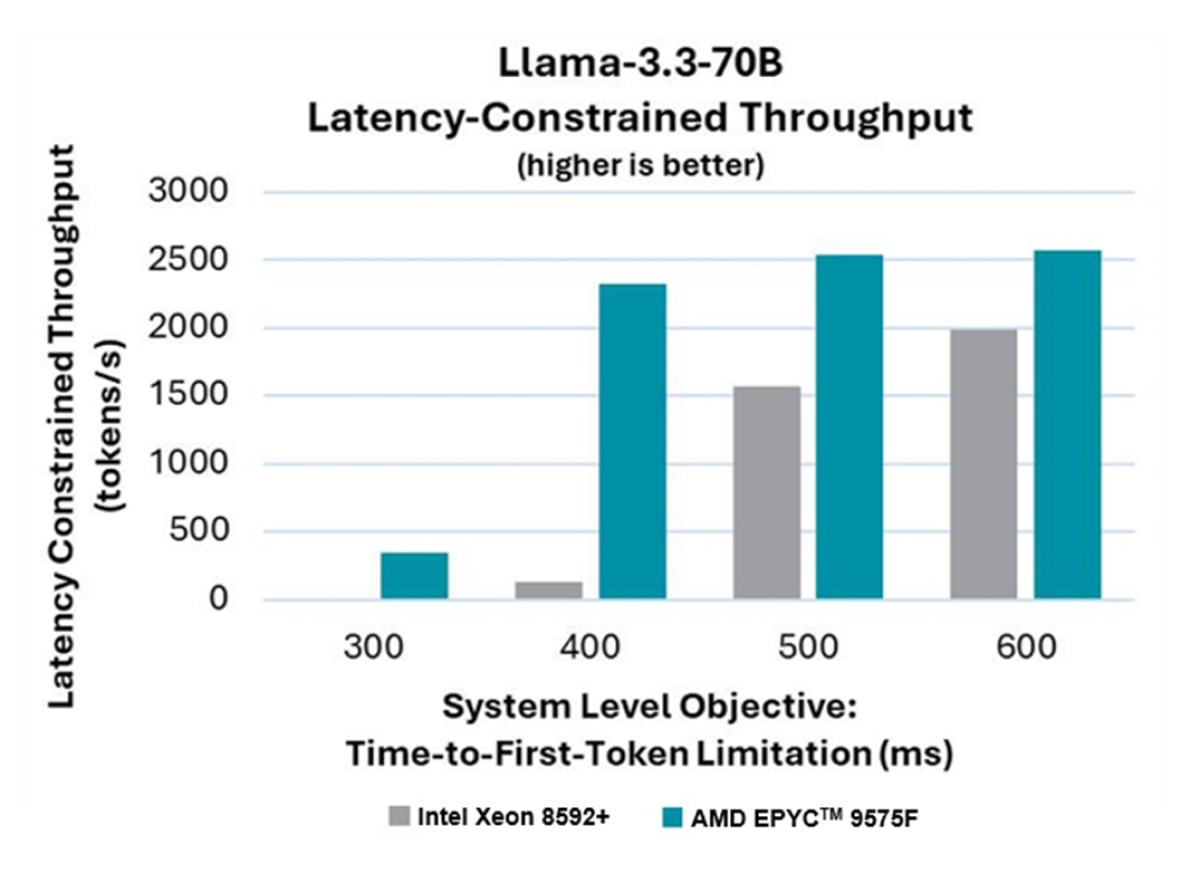
図2:レイテンシ制約付きスループットと最初のトークン生成時間(TTFT)制約の関係
AMD EPYC™ 9575FプロセッサとIntel Xeonホストプロセッサの比較分析は、レイテンシ制約のある推論サービスにおいてAMD EPYC™ 9575Fホストプロセッサが圧倒的な性能優位性を持つことを示しています。GPUシステムのホストCPUとして使用した場合に、高い効率性と応答性で業界をリードしていることが明らかになりました。
テスト構成
| Model Tested | Llama3.3 70B |
| Data Set | Sonnet3.5-SlimOrcaDedupCleaned [2] |
| Runtime | vLLM v1.0, TP8, MAX_NUM_REQS=512, NUM_PROMPTS=512 |
| Test Runs | 5 times, average used |
| Server Command | vllm serve ${model} –dtype half –kv-cache-dtype auto -pp 1 -tp 8 |
| Client Command | python /workspace/vllm/benchmarks/benchmark_serving.py –model ${model} –tokenizer ${model} –dataset-name hf –dataset-path ${dataset_id} –num-prompts ${num_prompt} –goodput ttft:${slo_ttft} –trust-remote-code –save-result –hf-split train –percentile-metrics ttft,tpot,itl,e2el |
| 項目 | Intel Xeon 8592+ホストプロセッサ | AMD EPYC™ 9575Fホストプロセッサ |
| サーバー | Supermicro SYS-821GE-TNHR | Supermicro AS-8125GS-TNHR |
| CPU | 2ソケット Intel Xeon Platinum 8592+(合計128コア) | 2ソケット AMD EPYC™ 9575F(合計128コア) |
| CPU最大クロック周波数 | 3.9 GHz | 5.0 GHz |
| GPUアクセラレータ | 8台 H100 SXM 80GB HBM3 | 8台 H100 SXM 80GB HBM3 |
| メモリ | 1TB(16×64GB DDR5-5600) | 1.5TB(24×64GB DDR5-6000) |
| OS | Ubuntu 22.04.3 LTS, kernel 5.15.0-118-generic | Ubuntu 22.04.3 LTS, kernel 5.15.0-117-generic |
参考資料:
1.ベンチマーク MLPerf Inference: Datacenter [LLM – Q&A インタラクティブ参照]
2. Sonnet3.5-SlimOrcaDedupCleaned
3. 「Maximize GPU Efficiency with AMD EPYC Processors」ホワイトペーパー







